
PwCコンサルティングが2026年2月に公開したレポート 『迫るAI社会と主要業界の変貌:AIによる破壊と創造』 を読みました。
AIが社会をどう変えるか。産業構造はどう再編されるか。通信、製造、エンタテイメント——各業界の未来像が描かれた、読み応えのあるレポートです。
正直に言います。読み終えて最初に思ったのは、 「これ、大企業だけの話だと思ったら終わりだ」 ということでした。
レポートが描くAI時代の全体像
PwCが描くAI時代の要点を、自分なりに整理します。
まず、AI産業のバリューチェーンにおける 「稼ぎどころ」が移動する という指摘。
AI産業バリューチェーンにおける高付加価値帯は、これまでのインフラ層(半導体、クラウド、データセンターなど)から、よりユーザー側に近い領域にシフトする1
今はGPUやデータセンターなどのインフラに巨額の投資が集中しています。しかしこれらが汎用化すると価格競争が激化し、インフラだけでは利益を確保しにくくなる。次の主戦場は 「AIを使って何をするか」 ——つまり、アプリケーションやAIエージェントを設計し、各産業に実装するレイヤーに移っていきます。
さらに、AIはデジタル空間にとどまりません。フィジカルAI(現実世界で自律的に判断・行動するAI)が広がり、あらゆるモノにAIが搭載される 「AIoT(AI of Things)」 の時代が来ると。その先には、社会インフラそのものにAIが組み込まれる 「AIoS(AI of Society)」 という概念すら見えてくる。
壮大な話です。半導体やデータセンターへの兆円単位の投資、ヒューマノイドロボットが工場を動かす未来、AIがエンタメの制作から流通までを変えていく世界。スケールの大きさに圧倒されます。
でも、このレポートの中に、 自分が最も共感し、最も重要だと確信した一節 がありました。
自分が最も注目した部分:「独自データ戦略」
レポートの第1章で、AI時代に求められる5つの経営アジェンダが示されています。競争戦略、制約前提の事業戦略、グローバルアーキテクチャ、ユーザーインタフェース形成——どれも重要です。でも、自分が最も刺さったのは5番目でした。
AI時代においては、他社も使える汎用データやオープンデータだけでは、持続的な優位性を確保できません。自社だけが持つデータ資産をいかに蓄積・活用できるかが非常に重要になります1
独自データ戦略。
これこそが、自分がデータ基盤の仕事を通じて、ずっと感じてきたことです。
多くの企業が「ビッグデータ」「オープンデータ」という言葉に引っ張られて、 大きなデータ、外のデータ を追いかけます。政府の統計データ、業界レポート、SNSのトレンドデータ。もちろん、これらには価値があります。
でも、AI時代に本当に差がつくのは、 自分たちだけが持っている、他では絶対に手に入らないデータ です。
考えてみてください。ChatGPTやGeminiに質問すれば、インターネット上の公開情報に基づいた回答が返ってきます。誰が聞いても、ほぼ同じ回答です。
では、こう聞いたらどうでしょう。
「うちの過去3年の顧客傾向を分析して」「先月の売上が落ちた原因を教えて」「この地域の住民が本当に求めているサービスは何?」
AIは答えられません。 そのデータを持っていないからです。
逆に言えば、そのデータを持ち、AIに渡せる状態にしている組織は、他にはできない意思決定ができる。AI時代の競争優位性とは、モデルの性能差ではなく、 「AIに何を知らせることができるか」の差 なのです。
「AI Readyなデータ」って何だろう? でも書きましたが、AIの性能がいくら上がっても、渡すデータが整っていなければ、アウトプットの質は上がりません。入力の質が出力の質を決める。この原則は、どれだけAIが進化しても変わらないはずです。
中小企業の足元にある「唯一無二のデータ」
ここで大事なことを言わせてください。
独自データは、大企業の特権ではありません。
中小企業にも、ユニークなデータは山ほどあります。むしろ中小企業のほうが、 「替えが効かないデータ」 を持っていることが多い。
- 地域の宿泊施設が10年かけて蓄積した予約データと顧客情報
- 製造業の中小企業が持つ、品質管理の記録と不良品の傾向データ
- 地方DMOが集めてきた、観光客の動態データと満足度調査
- 老舗の小売店が肌で知っている、季節ごとの売れ筋パターン
- 建設会社の現場監督が経験から積み上げた、工期と天候の関係
これらのデータは、GoogleにもAmazonにもOpenAIにも手に入りません。 あなたの組織だけが持つ、世界で唯一のデータ です。
PwCが「独自データ戦略」と呼んでいるものの核心は、難しいことではないと思っています。 自分たちの足元にあるデータに目を向け、それをAIが使える形に整えること。 それが出発点です。
オープンデータや統計データは、全員が同じ土俵に立つための共通の地図です。でも、 差がつくのは、あなただけが持っている情報をAIに渡せるかどうか です。
データ活用で本当に必要だったもの で書いたように、大事なのは「何のデータを見たいか」を言語化できるかどうか。大量のデータを集めることではなく、自分たちの意思決定に本当に効くデータを見極め、整えること。ここが第一歩です。
AIが「完全な記憶」を持つまで、データベースが必要だ
もう一つ、伝えたいことがあります。
AIの進化は目覚ましい。でも、現時点のAIには 「完全な記憶」がありません。
ChatGPTもGeminiも、会話の文脈は覚えています。でも、あなたの会社の全データを記憶しているわけではない。セッションが切れればリセットされるし、社内の業務データにはそもそもアクセスできない。AIは賢い。でも、 「知っている」ことと「覚えている」ことは違います。
AIが完全な記憶を持つ日——つまり、あらゆるデータを永続的に保持し、文脈を理解して自律的に判断できるようになる日——は、まだ先の話です。では、その間を埋めるものは何か。
データベースです。
この問題を解決する仕組みとして注目されているのが、PwCのレポートでも触れられている RAG(Retrieval Augmented Generation:検索拡張生成) です。
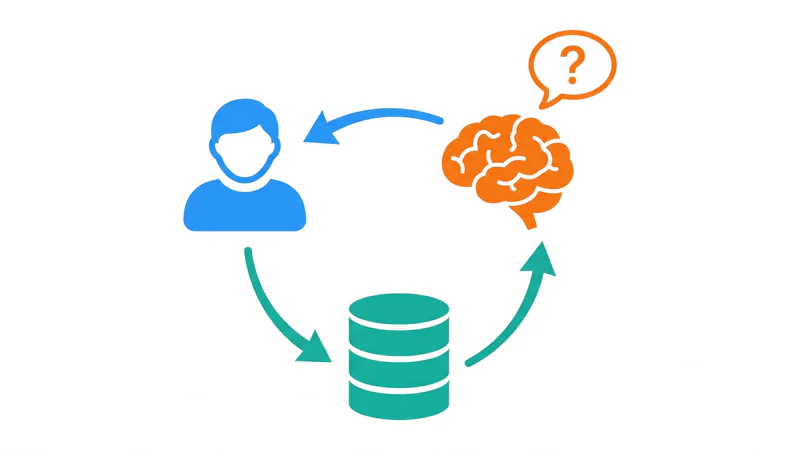
RAGの仕組みはシンプルです。AIに質問が来たら、まずデータベースから関連する情報を検索して取り出す。その情報をAIに渡して、「この情報をもとに答えて」と指示する。すると、AIは あたかもその情報を最初から知っていたかのように 、的確に回答してくれます。
NotebookLMとは? で紹介したGoogleのNotebookLMは、まさにこのクローズドRAGを使っています。アップロードした資料だけを参照して回答するから、ハルシネーション(嘘)が極めて起きにくい。回答には必ずソースへの引用が付く。
ここで注目してほしいのは、 RAGの精度はデータベースの質で決まる ということです。
AIが「都合よく記憶のように」データを読み取り、「あたかも知っていたかのように」答えてくれる世界——これは、すでに目の前に来ています。PwCが提唱する マルチリージョナルRAG の概念も、まさにこの延長線上にあります。
でも、読み取るべきデータベースがなければ、この仕組みは動きません。 AIが完全な記憶を持つまでの間、データベースがAIの記憶装置として機能する時代が続く。 だからこそ、今、 データ基盤(データウェアハウス) を整えることに大きな意味があるのです。
データウェアハウスって結局何なの? で解説していますが、データウェアハウスとは、組織のさまざまなデータを一か所に集め、分析やAI活用に使える状態に整理した「データの倉庫」です。これが、AI時代における組織の記憶装置になります。
デジタル化されていないデータは、AIにとって「存在しない」
ここまで読んで、こう思った方もいるかもしれません。
「うちにはデータベースなんてないし、独自データと言われても…」
その気持ちは痛いほどわかります。でも、厳しい現実を伝えさせてください。
デジタル化されていないデータは、AIにとって存在しないのと同じです。
紙の帳票に書かれた10年分の売上記録。ベテラン社員の頭の中にある顧客情報。Excelで属人的に管理されている在庫データ。これらは、そのままではAIに渡すことができません。RAGも動きません。AIの恩恵は受けられません。
PwCのレポートは、AIの恩恵として「知的労働の生産性を大幅に向上させ、タスク指示から完了報告まで自律的に代行してくれる」と述べています1。しかし、この恩恵を受けるには前提条件がある。 AIがアクセスできる形でデータが存在していること です。
だからこそ、 どんな事業者であっても、デジタル化を進めてAIの恩恵を手に入れられるかどうかが、何よりも重要 なのです。
これは「最先端のDXをやれ」という話ではありません。まずは今あるデータをデジタルの世界に移すこと。Excelでもいい。Googleスプレッドシートでもいい。手書きの台帳をCSVにするだけでもいい。デジタルの世界にデータを置く。その上で、データベースに集約し、AIが読み取れる状態にしていく。
「データ活用が全てを決める」?そんなわけない。 でも書きましたが、データだけで意思決定はできません。現場の勘・経験・度胸(KKD)は尊い。でも、その勘と経験を データで裏付け、AIと一緒に検証する サイクルが回ったとき、意思決定のスピードと精度は劇的に変わります。
AIと相談した上で意思決定をし、未来への投資判断を行う。このサイクルを回せる組織と回せない組織の差は、今後ますます広がっていくでしょう。
中小企業のデータ活用を支援してきて、確信していること
自分はこれまで、地方の観光DMOや中小企業のデータ活用を支援してきました。
ある地域のDMOで、それまで紙とExcelで管理していた宿泊データをデータベースに集約し、ダッシュボードで可視化しました。特別なAIを導入したわけではありません。ただ、 「データを見える化した」だけ です。
それだけで、会議の質が変わりました。
「たぶん、最近は○○からのお客さんが増えている気がする」——これが、「先月の○○エリアからの宿泊者数は前年比15%増。特に40代ファミリー層が伸びている」に変わった。根拠のある仮説が立てられるようになり、次の施策の議論がはるかに具体的になった。
なぜ今、観光地経営を「科学」するのか で書いた「科学する」の本質は、まさにこのサイクルです。仮説を立て、データで検証し、次のアクションにつなげる。
今後、このサイクルにAIが加わります。データベースに蓄積された独自データをRAGで参照し、AIが「この傾向が続くなら、来月はこの施策を検討してはどうですか」と提案してくれる。人間がAIと対話しながら、根拠を持って意思決定する時代は、もう始まっています。
大事なのは、 データの量ではなく、データがAIに渡せる状態にあるかどうか です。小さなデータでも、整理されていれば、AIは力を発揮します。
なぜ自分は「日本のデータ基盤」を支えたいのか
PwCのレポートが描く未来では、AIが社会のあらゆるところに浸透し、産業構造を根本から変えていきます。その波は、大企業だけでなく、中小企業にも確実に届きます。
でも、正直な現実として、日本の中小企業の多くは、この波に乗る準備ができていません。データはデジタル化されておらず、データベースも整備されておらず、AIを活用する基盤がない。
大企業と中小企業の差は、AIモデルの性能差ではありません。「AIに渡せるデータを持っているかどうか」の差です。
この差を放置すれば、AI時代のデジタルデバイドはますます広がります。PwCが警鐘を鳴らす「寡占市場化」の問題は、テック企業間だけの話ではないと思っています。データ基盤を持つ組織と持たない組織の間にも、同じ構造的な格差が生まれます。
自分がDataBakeを立ち上げた理由は、ここにあります。
日本の中小企業が、規模に関係なく、AIの恩恵を受けられるようにしたい。 そのために、データ基盤の仕組み作りを支援していきたい。
巨大なデータや最先端のAIモデルに振り回されるのではなく、 自分たちの足元にあるデータに目を向ける。 それをデジタル化し、データベースに整え、AIと対話できる状態にする。そこから現場を変え、意思決定のスピードを上げ、未来への投資判断を磨いていく。
PwCのレポートが描く壮大なAI社会の実現には、ビッグテックのインフラ投資だけでなく、 地方や中小の事業者一つひとつがデジタル化を進め、独自データを活かせるようになること が不可欠だと、自分は信じています。
こういった背景で、自分は日本のデータ基盤の仕組み作りを支援していこうという志を持っています。規模の大小ではなく、 「自分たちのデータで、自分たちの意思決定を強くする」 ——そのための基盤を、一つずつ丁寧に作っていく。それが自分の仕事です。
AI時代は、「データを持っている側」が強い
PwCのレポートを通じて、改めて確信しました。
AI時代の本当の武器は、最新のGPUでも、巨大なデータセンターでもありません。
あなたの組織だけが持っている、唯一無二のデータ。 そして、それを AIが読み取れる形で整えるデータ基盤。 この2つです。
オープンデータや統計データは、全員が同じ土俵に立つための共通の地図にすぎません。差がつくのは、 「自分だけが知っていることを、AIに渡せるかどうか」 です。
AIが完全な記憶を司るようになるまでの間、データベースがAIの記憶装置になる。だからこそ、今、データを整えることには確かな価値がある。
まずは足元を見てください。あなたの組織が何年もかけて蓄積してきたデータ。あなたの地域が持つ、どこにも公開されていない情報。それこそが、AI時代における最大の資産です。
その資産を活かす準備を、今から始めませんか?
Footnotes
-
PwCコンサルティング「迫るAI社会と主要業界の変貌:AIによる破壊と創造」(2026年2月25日公開) ↩ ↩2 ↩3